
In the previous phase, I had worked on adding the following features - restrict circuit elements #397 and grading #390. Apart from that I also worked on increasing the test coverage of backend #241. Turns out, it’s very easy to get started on a feature but a lot of work had to be done in order to get these features into production. All major PR’s have been merged from the first phase.
After the work, first evaluation happened from the 24th to 28th June and …

I passed! Yay!
For this phase, I’ll be targetting 2 major feature additions - Search and SEO improvements, and Improving featured circuits detections. I’ll be starting out with search improvements.
case search In the last week, I had been researching all the search techniques available. There are two broad choices that we had - Postgres full-text search and Search Engines (like Solr and Elasticsearch). I tried benchmarking all our options over this week to come up with a suitable choice. All tests were done locally.
when pg_search An initial implementation of the search for projects has already been done using pg search. However, the query timings are comparatively slow.

But using pg_search is far better than using custom indexes and queries using the LIKE operator. LIKE queries can be very inefficient on unindexed columns. Sometimes even when the column is indexed, in the worst cases, there might be some leading wildcard in the query, that requires all the indexes to be scanned. There are also other powerful tools that Postgres’s full-text search provides, such as lexical analysis or tokenization, morphological analysis and ranking. The only disadvantage of full-text search over LIKE queries in the size of the indexes, which are very large.
when solr Solr is a widely popular alternative to Elasticsearch. It is built over Lucene and can be easily integrated into a rails app using sunspot. During local testing, memory requirements of Solr on an average were 400-500MB and during indexing went as high as 700MB. The indexes that were created required 100MB memory.
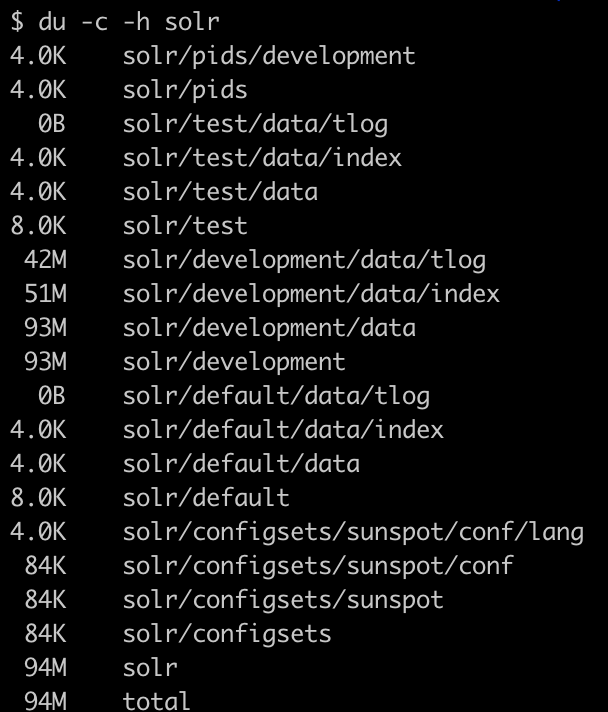
Once indexes were created, queries were lightning fast(almost 10 times faster locally than pg_search)

when elastic_search Query timings for Elasticsearch and Solr were very comparable, but Elasticsearch came out to be more memory-intensive than Solr. It required 1.2GB memory on startup! This makes Elasticsearch impossible to operate on a 2GB VPS without restricting the heap size like so -
ES_JAVA_OPTS="-Xss256k -Xms512m -Xmx512m" ./elasticsearch-7.2.0/bin/elasticsearch
end Search.conclude? Currently, CircuitVerse has around 25k records. Engines like Elasticsearch and Solr are made to work with millions of records, so currently, pg_search suffices for our requirements. However, in the future, the records might go up to a few hundred thousand. Then having Solr/Elasticsearch setup will come in very handy. Between Elasticsearch and Solr, we’ve currently decided to go with Solr and as it provides a comfortable middle ground between full-text searching and search engines. We’ll be implementing both pg_search and Solr and the option to use either will be configurable.
Week.next? In the coming week, I’ll be working on completing search implementation using both Solr and pg_search. I’ll also be aiming to add the required UI changes. It’s going to be Awe..
Written on July 7th, 2019 by Ankit KatariaWait for it…